程序编译过程:
源程序 -> 词法分析程序 -> 语法分析程序 -> 语义分析程序 -> 中间代码生成程序 -> 代码优化程序 -> 目标代码生成程序 -> 目标程序
语法分析
例:
<句子> → <主语><谓语>
<主语> → <代词><名词>
<代词> → 你 | 我 | 他
<名词> → 老王 | 大学生 | 英语
<谓语> → <动词><直接宾语>
<动词> → 是 | 学习 | 热爱
<直接宾语> → <代词> | <名词>
“我是大学生”符合以上规则,是句子。“我大学生是”不符合上面规则,不是句子。
<句子> → <主语><谓语>
→ <代词><谓语>
→ 我<谓语>
→ 我<动词><直接宾语>
→ 我是<直接宾语>
→ 我是<名词>
→ 我是大学生
符号和字符串
字母表
字母表即符号集,例如汉字的字母表包括汉字,数字标点等,C语言包括if,while之类的保留字组成。
符号串
由字母表中的符号组成的任何又穷序列(顺序很重要)。例如A = {a, b, c}的符号串有a,b,ab,ba, aa等等。
符号串的头尾,固有头固有尾
abc的头是 ε, a, ab, abc,除abc外均为固有头。尾是ε, c, bc, abc,除abc外均为固有尾。
符号串方幂
x = AB。x^0 = ε。x^1 = AB。x^2 = ABAB。x^3 = ABABAB。
符号串的集合
A = {a, b}。B = {c, d}。AB = {ac, ad, bc, bd}。
文法定义
G(VN, VT, P, S)。
VN为非终结符(例如<谓语>,可以继续转换。通常用大写字母表示,例如A)
VT为终结符(例如“老王”,可直接匹配,不能再向下转换。通常用小写字母表示,例如a)
P(规则,例如<主语> → <代词><名词>。又例如S →Aa)。
S起点(例如<句子>就是起点)
文法类型
3型∈2型∈1型∈0型,3型最严谨,向右兼容。
0型递归文法
a→b,a至少含1个非终结符,b为任意。
凡是递归可枚举的都是0型,包括A→ε,aA→aa等情况。
1型上下文有关文法
a→b,a至少含1个非终结符,b不为ε。
0型除去ε的情况就是1型。也就是非终结符不能为ε。
包括aA→aa等情况。
2型上下文无关文法
a→b,a必须是非终结符(only one)。
不包括aA→aa等情况。
可以A→aa。
3型正规文法
非终结符转换时头必须有一个终结符。例如:
S→aB
S→bA
A→a
A→aS
A→bAA
B→b
B→bS
B→aBB
语法树
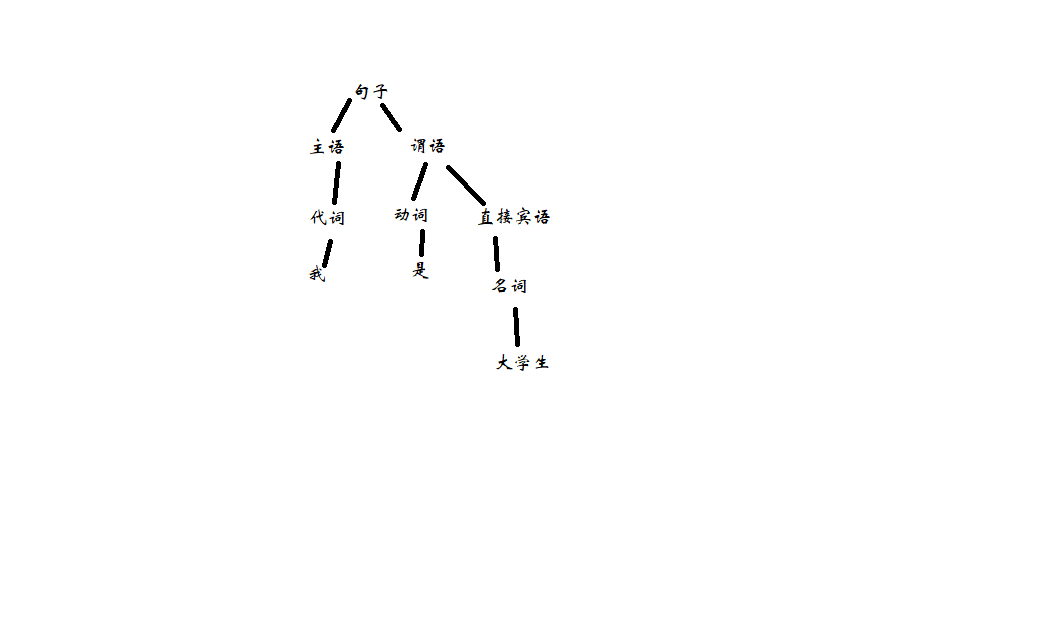
句型分析
- 自顶向下语法分析(由S向句子推,最终和句子匹配,看能否得到句子)
- 自底向上语法分析(由句子向S推,最终看能否得到S)
词法分析
输入源程序;扫描、分解字符串,识别出一个个单词(定义符、标识符、运算符、界符、常数)
词法分析输出
读入源程序,输出担此符号。单词符号可分为以下5种:
关键字(if,else,while,int等)
标识符(a,fun,val等自定义的变量名)
常数(1,1.2,true,“abc”)
运算符(+,-,=,<=,==)
界符(,;’)’)等。
词法分析输出单词符号常常采用二元组形式(单词种别,单词自身值)。
阶段
扫描阶段:从左向右扫描输入源程序,删除注释、压缩空白字符;
词法分析阶段:按照语言的词法规则识别各类单词,并产生相应的单词符号。
正规文法
<标识符> → l | l <字母数字>
<字母数字> → l | d |l <字母数字> | d<字母数字>
(l字母,d数字)
例如:
A→aB
A→a
正规式
a {a}
a|b {a,b}
ab {ab}
(a|b)(a|b) {aa,ab,ba,bb}
a* {ε,a,aa,aaa…}
(a|b)* {ε,a,aab,abaa…所有a,b组成的串}
(a|b)*(aa|bb)(a|b)* {aaabbaab……}
有穷自动机
确定有穷自动机(DFA)
DFA M = (K, ∑, f, S, Z)
K:有穷集,每个元素称为一种状态(图表示就是点集)。
∑:有穷字母表,每个元素称为一个输入符号,所以也叫输入符号表(图表示就是边集)。
f:转换函数,一个节点通过某条边到另一个结点(或自身)。
S:唯一一个初态(起点)
Z:终态集。(就是终点的集合)
不确定有穷自动机(NFA)
NFA M = (K, ∑, f, S, Z)
K:有穷集,每个元素称为一种状态(图表示就是点集)。
∑:有穷字母表,每个元素称为一个输入符号,所以也叫输入符号表(图表示就是边集)。
f:转换函数,一个节点通过某一类边到另外许多结点的集合(或自身)。
S:初态集(多个起点)
Z:终态集。(就是终点的集合)
很容易发现,不确定有穷自动机和确定有穷自动机的区别就是DFA每个结点每类单向边只有一条,且起点只有一个,而NFA可以有多条,且起点可以有多个。例如NFA中S—a—>A,S—a,b—>S,S—a,b—>D,但DFA不允许,a,b由S指向其他结点(或自身)的话只能存在一条。
正则式转自动机
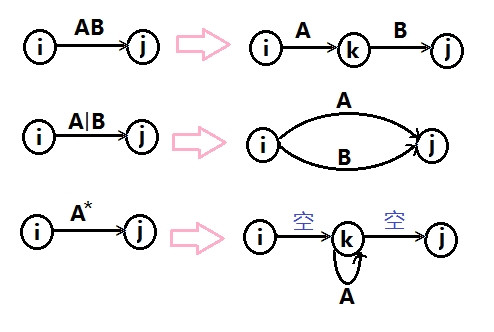
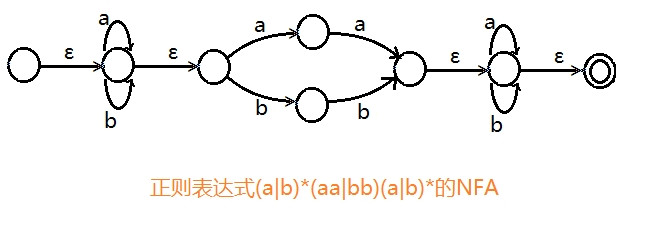
正规文法转自动机
正规文法由于为第3型文法,所以S→aA,S为起点,→为边,a为边名,A为下一个结点。

